One variant of the wing_nut family — ground-truth CadQuery, STEP, mesh, 4-view, and numeric QA.
17,900
Vision2Code img2cq
verified parts · 4-view → CadQuery
2,400
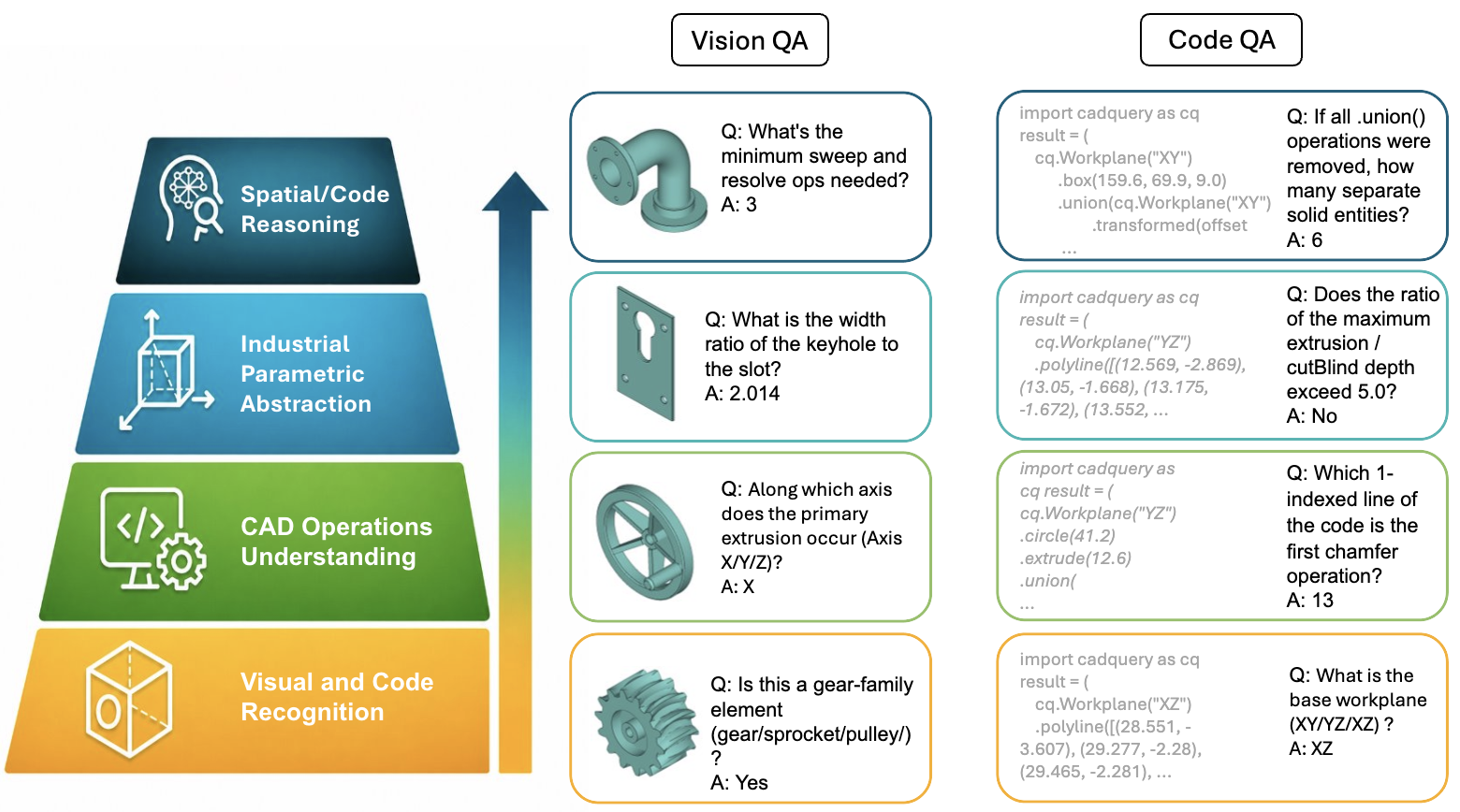
Vision QA · Code QA qa_img qa_code
paired image / code numeric items
748
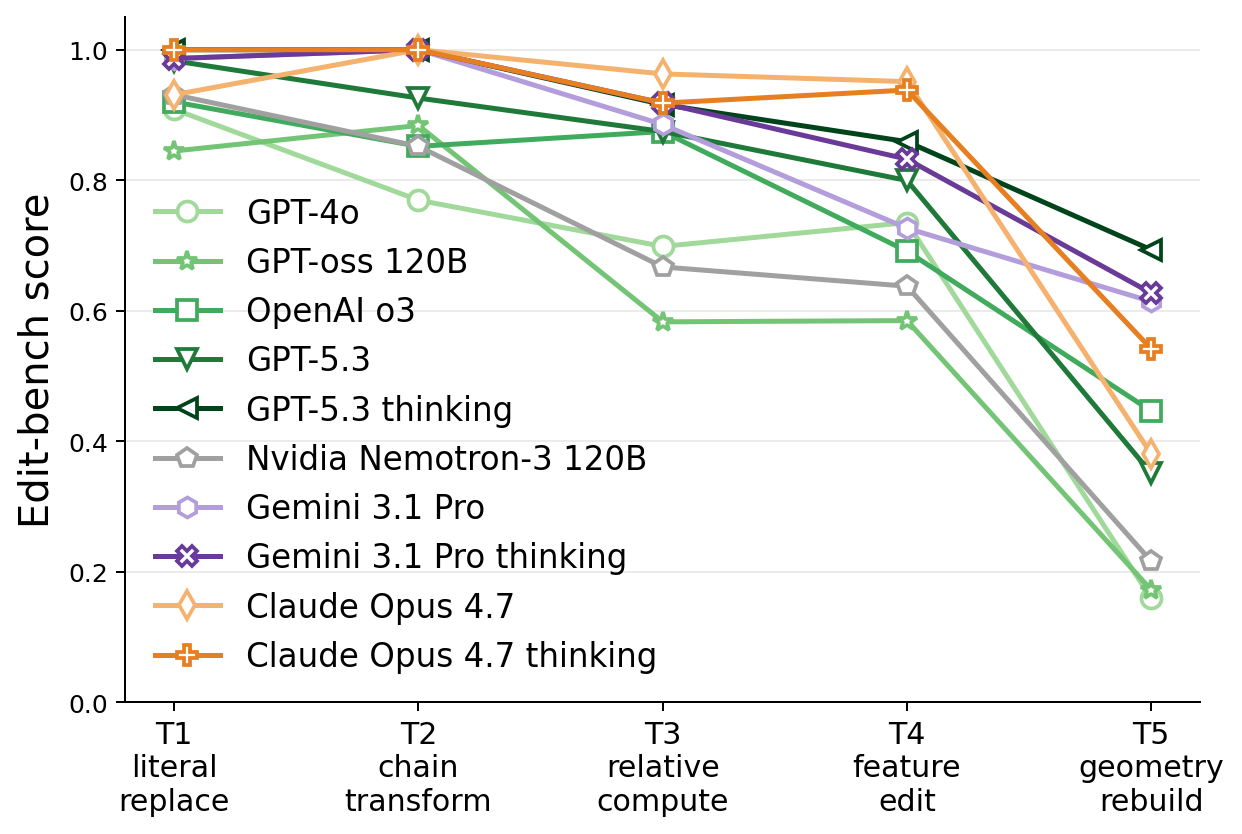
Code Edit edit_code
before/after edit pairs · T1–T5

106 industrial part families spanning fasteners, transmission, structural, fluid, panels, hardware, and enclosures. 49% of families (52/106) are anchored to real specification tables across 47 ISO / DIN / EN / ASME / IEC codes.
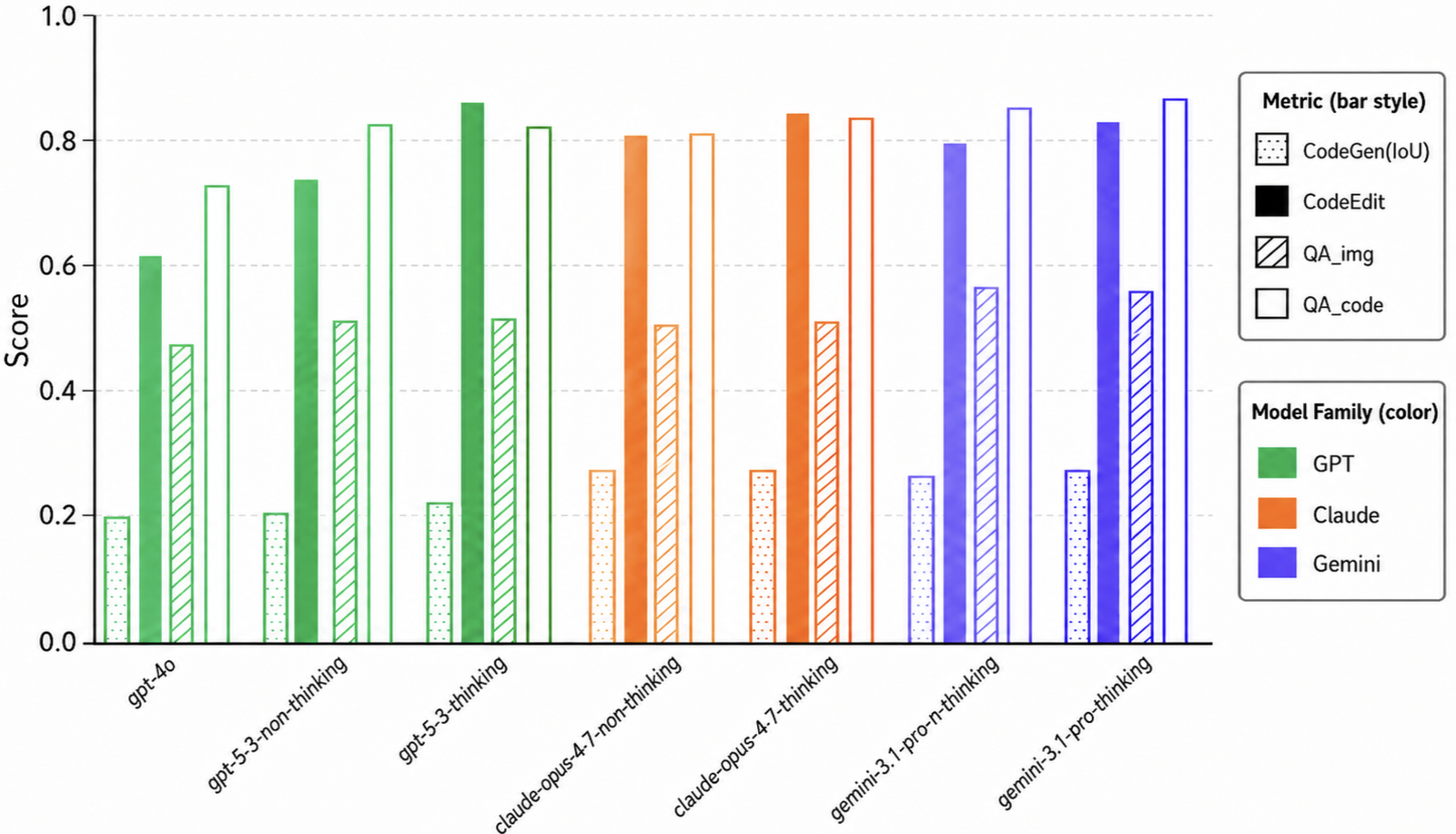
BenchCAD is a unified, capability-decomposed benchmark for industrial CAD reasoning — 17,900 execution-verified CadQuery programs across 106 industrial families, every family expert-curated and grounded in industrial standards. It evaluates models through four matched tasks: Vision2Code, Vision QA, Code QA, and Code Edit.
Three releases: BenchCAD (17,900 verified parts) · BenchCAD-QA (2,400 paired image/code numeric QA items) · BenchCAD-Edit (748 verified edit pairs).
Operation surface covers 46 distinct CadQuery ops including helix, twistExtrude, polarArray, loft, and sweep.